记录一次爬取超星练习题的过程
起因
毛概的线上考试明确会在超星的练习题题库中抽取,而练习题题库的量还挺大。但是好处在于可以无限次联系重做,就准备扒下来到时候开卷开始的时候直接搜索。加上很久没写过爬虫了,也打算回忆一下
准备
其实也没啥准备的,环境就是python 下一些常用的包像requests,Xpath就行了
过程
首先就是常规的F12拿到请求网址和headers。然后先看下请求相应是不是正常的200
url="https://mooc1-2.chaoxing.com/exam/test/reVersionPaperMarkContentNew?courseId=213234829&classId=29192518&p=1&id=21465417&ut=s&examsystem=0&cpi=141162163"
Cookie='web_im_hxToken=YWMtotEpyoQ2Eeq0%2dlsulKS6XKKlE4D%2d6RHksYgJxSsb8jLHHeVQxZ4R6I54NZkDrrDYAwMAAAFxn3N9VQBPGgB%5fgjI4SJAOd90OVC0UdF1kUIdPtkM3olp7T%2dBBBh%5fxvQ; web_im_tid=59499679; web_im_pic=http%3a%2f%2fimg1%2e16q%2ecn%2fa56626a15a1c2cc92d0b0972e3d086ba%3f; web_im_name=%u8d75%u4fca; uname=201810411128; lv=2; fid=403; _uid=83184198; uf=d9387224d3a6095b9dbf35210ecb91455e22c3171ae3f6e05407199b7d24e63f493f503defad0f4cca762b5ff7d6299dd807a544f7930b6abeaaa6286f1f175415007a0a784c07b2ce71fc6e59483dd3fa59c9312adf9fc5d53d56f27dc57dd6dee7d1bbb946cfa2; _d=1592383146982; UID=83184198; vc=BA285D7D5355E87F3911EAD85C68BCBD; vc2=7FFC7399F8A9362884FA77D71910C889; vc3=IgC76YYu8%2FuMpGQdO1HPHyI3bg98rJkP99Xb%2FbvsXxROMSYSlYd7At0mooGPV8ZclA9cCOMeO4ej4F6u6OJ7kbuARswMJ8aYdFvBldcLh7SSXIEqTBW0m6Jwjg3dd6RGuEM3U83yyM7qVaKRZw6g2p9SrQw9v2CoUcS2TilZhT4%3D05c85b78d469c698041df555181cd166; xxtenc=b34cdd116542a9d71490e0b392ee5266; DSSTASH_LOG=C_38-UN_1804-US_83184198-T_1592383146984; spaceFid=1648; rt=-2; tl=1; k8s=e12004236a9b305941873f3923a06099ddcda725; jrose=2D37FD3D071668B8F7B134D7FCAF66CF.mooc-1369212770-cmw1d; route=c010ccedb771f8b7c7793c67ee1d2aae; thirdRegist=0'
headers={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Connection': 'keep-alive',
'Cookie': Cookie,
'Host': 'mooc1-2.chaoxing.com',
'Referer': 'https://mooc1-2.chaoxing.com/exam/test?classId=29192518&courseId=213234829&ut=s&enc=939d5f023f8e8425700afadc13413199&cpi=141162163&openc=2e3ca0126417e95714ede1a4dea89b84',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'
}
r=requests.get(url,headers=headers)
html=r.text
其实headers中应该重要的就是Cookie和referer和user-Agent.其他应该不是必须的(没测过)。
这样就拿到请求html报文了
然后用etree解析一下
con=etree.HTML(html,parser=etree.HTMLParser(encoding='utf-8'))
etree能够格式化html页面,方便后面用Xpath提取标签
然后就需要分析我们需要的题目,选项,答案分别在什么标签下。然后使用Xpath把他们提取出来就行了,Xpath的使用方法还是比较简单。注意的就是//表示在子孙节点中寻找,/表示仅在子节点中寻找
另外实际使用过程中发现Xpath简单的寻找节点还不能满足需求,比如爬取中发现有些题目是直接写在li标签中的,而有些题目是在li标签下的a标签中的。也不知道为什么会出现这种不规范的情况。导致最开始爬取的时候会缺失题目,导致答案选项题目对应不上,非常致命
解决方案呢参考了网上Xpath的一些进阶使用方法,比如使用descendant-or-self::*去表示当前节点及其所有子节点,当然这导致了爬取出来的信息可能需要一些简单的清洗。
获取节点的代码如下
title=con.xpath("//div[@class='wrap1000 clearfix con']//div[@class='Cy_TItle clearfix']/div[@class='fl clearfix']/descendant-or-self::*/text()")
title=list(filter(lambda x: len(x)>6,title))
choice=con.xpath("//div[@class='clearfix']//*/text()")
ans1=con.xpath("//div[@class='wrap1000 clearfix con']//div[@class='Py_answer clearfix']/span/text()")
ans2=con.xpath("//div[@class='wrap1000 clearfix con']//form/div[@class='Py_answer clearfix']/span/i/text()")
title的处理是为了过滤一俩个题的题号和题目卸载不同的标签里,所以就在他title中通过限制长度把题号去掉了。
数据处理
上面拿到了所有的题目,选项和答案标签,接下来就要进行数据处理了,本来应该是直接写入数据库的,但最开始没想到后面还需要进行去重,而且当时也不会python和数据库交互,就写入文件了。
f=open("C:/Users/85148/Desktop/test1.txt","a",encoding='utf-8')
for i in range(100):
print("正在写入第"+str(i+1).replace("\r","").replace("\n","").replace("\t","").lstrip()+"题")
# 写入题目
f.write(str(i+1)+" "+title[i]+"\n")
# 写入选项 缺少的俩个题目特殊处理
if(i<70):
f.write("A:"+choice[(i*4)+0]+"\n")
f.write("B:"+choice[(i*4)+1]+"\n")
f.write("C:"+choice[(i*4)+2]+"\n")
f.write("D:"+choice[(i*4)+3]+"\n")
# 写入答案
# 选择题
if(i<70):
f.write(ans1[i*2].replace("\r","").replace("\n","").replace("\t","").lstrip()+"\n")
f.write("\n")
# 判断题
else:
f.write(ans2[(i-70)]+"\n")
f.write("\n")
print("写入完成")
然后就是重复提交白卷,多次拿到题目。但是这样拿到了是没有去重处理的,而且你也不知道你到底爬取完整个题库没有。
然后就需要做去重操作了,我这里使用JAVA去操作数据库的
首先是要获取数据库连接
public static Connection getConection() throws ClassNotFoundException, SQLException {
String userName="root";
String password="123456";
String driveName="com.mysql.jdbc.Driver";
String url="jdbc:mysql://localhost:3306/db_tiku?characterEncoding=utf8&useSSL=true";
Connection connection =null;
Class.forName(driveName);
connection= DriverManager.getConnection(url,userName,password);
return connection;
}
然后就是把最开始写入文件的题库又再次读到数据库里面,数据库我建了俩张表,分别表示选择题和判断题
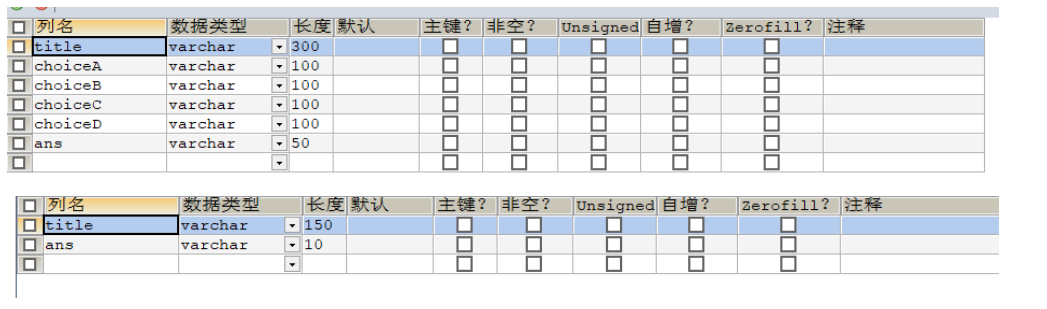
然后就是常规写入数据库了,根据最开始写入文件的顺序去写入数据库,因为最开始是一100题一套写入文件的,所以写入数据库的时候也得按照这个顺序来,而且还要注意处理空行,以及去掉写入文件时添加的序号,我这里偷懒了,直接用的subString,不太好,最后发现有一些数字没去除干净,最好使用正则或者其他什么方法
public static void baseDao(Connection con1,Connection con2) throws FileNotFoundException, SQLException {
Scanner scanner=new Scanner(new File("C:\\Users\\85148\\Desktop\\test1.txt"));
String choiceSql="insert into tiku_choice values (?,?,?,?,?,?)";
String judgeSql="insert into tiku_judge values (?,?)";
PreparedStatement pstmChoice = null;
PreparedStatement pstmJudge=null;
try {
pstmChoice = con1.prepareStatement(choiceSql);
pstmJudge = con2.prepareStatement(judgeSql);
} catch (SQLException throwables) {
throwables.printStackTrace();
}
while(scanner.hasNext()) {
for (int i = 0; i < 100; i++) {
// Choice choice = new Choice();
// Judge judge = new Judge();
//选择题
if (i < 70) {
for (int j = 0; j < 7; j++) {
if (j < 6) {
if (j == 0) {
pstmChoice.setString(j + 1, scanner.nextLine().substring(2));
} else {
pstmChoice.setString(j + 1, scanner.nextLine());
}
} else {
scanner.nextLine();
}
}
pstmChoice.executeUpdate();
System.out.println("写入了第"+(i+1)+"题");
}
//判断题
else {
for (int j = 0; j < 3; j++) {
if (j == 0) {
pstmJudge.setString(j + 1, scanner.nextLine().substring(2));
} else if (j == 1) {
pstmJudge.setString(j + 1, scanner.nextLine());
} else {
scanner.nextLine();
}
}
pstmJudge.executeUpdate();
System.out.println("写入了第"+(i+1)+"题");
}
}
}
con1.close();
con2.close();
pstmChoice.close();
pstmJudge.close();
}
这样就把所有文件中的题库写入数据库了,去重直接用GROUP BY关键字即可。eg. select * from xxx GROUP BY yyy 即可按yyy字段来去重,同时通过去重我们也可以看到每次新增了多少新题目来判断我们是否爬取完所有题目
最后,由于我是需要考试的时候查询,所以还需要把去重后的题目及答案重新写入文件。和前面类似,只不过这里换成了用java去做
public class out {
public static void main(String[] args) throws SQLException, IOException {
Connection con=null;
try {
con = chaoxin.getConection();
} catch (ClassNotFoundException e) {
e.printStackTrace();
} catch (SQLException throwables) {
throwables.printStackTrace();
}
if(con!=null){
String sql1=" select * from tiku_choice GROUP BY title";
String sql2="select * from tiku_judge GROUP BY title";
PreparedStatement pstm=con.prepareStatement(sql1);
ResultSet rs=pstm.executeQuery();
FileWriter fileWriter = null;
try {
fileWriter=new FileWriter(new File("C:\\Users\\85148\\Desktop\\out.txt"));
} catch (IOException e) {
e.printStackTrace();
}
while (rs.next()){
fileWriter.write(rs.getString("title")+"\n"+rs.getString("choiceA")+"\n"+
rs.getString("choiceB")+"\n"+rs.getString("choicec")+"\n"+
rs.getString("choiceD")+"\n"+rs.getString("ans")+"\n\n");
fileWriter.flush();
}
pstm=con.prepareStatement(sql2);
rs=pstm.executeQuery();
while (rs.next()){
fileWriter.write(rs.getString("title")+"\n"+rs.getString("ans")+"\n\n");
fileWriter.flush();
}
System.out.println("写入完成");
fileWriter.close();
}
}
}
这样就搞定了!!!
测试&总结
最终考试的时候我就使用了我自己爬取的题库,基本全覆盖所有了的选择和判断。很成功。通过这次简单的练手也让我复习了很多东西。